Docs: https://docs.hugoblox.com/content/writing-markdown-latex/#callouts
Parameters
#0 : optional, positional Add the class “alert-{#0}” to the
assets/scss/blox-bootstrap/elements/_callout.scss).
*/}}Background
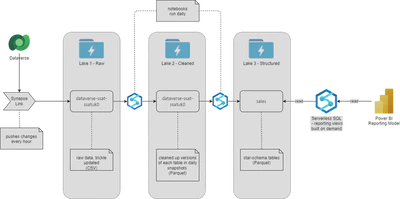
To enable us to run data analytics against our Dynamics 365 data history, I have created a datalake using Azure Datalake Storage V2, Synapse Analytics (Notebooks, Pipelines and Serverless SQL) and Dataverse Synapse Link, with Power BI as the reporting layer.
A high level view of the architecture looks like this (ignoring data sources other than Dataverse):
Parquet file format
All cleaned and structured data in our lake is stored in the Parquet format.
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Apache Parquet is designed to be a common interchange format for both batch and interactive workloads.
The advantages of this format over CSV are that it is good for storing big data of any kind, saves on cloud storage space by using highly efficient column-wise compression, and flexible encoding schemes for columns with different data types, and offers increased data throughput and performance using techniques like data skipping, whereby queries that fetch specific column values need not read the entire row of data.
However, it is not a format that can be trivially updated. Many data lake requirements never need to process updates, but on the occasions when it is needed, the common practice with parquet is to copy and transform, then replace the original.
Adding columns
The business requirement was to carry some new columns added to Dynamics through into our reporting data. Previously I have added these columns into our daily cleaned data snapshots, and also to the new daily snapshots of the fact table (this was done by editing and publishing the relevant notebooks). However this means that all previous snapshots are missing the columns, and this gives problems when trying to run views across the whole dataset.
If the fact and dimension tables were maintained in a database such as SQL server this would be a matter of adding the columns to the relevant tables and running a script to populate the rows.
However for the reasons above we have chosen to store this data in Parquet files, partitioned by the processing date of each daily snapshot.
As the format is effectively read-only, the overall approach is:
- iterate over the existing data one partition at a time (i.e. one daily snapshot at a time)
- read the snapshot into a dataframe
- check for the existence of each new column, and if not present insert as empty
- write out the data frame to a new set of data files
- replace the “in use” files with the new versions
Setting up configuration data
Docs: https://docs.hugoblox.com/content/writing-markdown-latex/#callouts
Parameters
#0 : optional, positional Add the class “alert-{#0}” to the
assets/scss/blox-bootstrap/elements/_callout.scss).
*/}}from datetime import datetime, date, timedelta
# configure columns to add
newcols = ['utm_campaign', 'utm_medium', 'utm_source']
# setup the source and sink locations
inputContainer = "sales"
inputStorageAccount = "MYSTORAGEACCOUNT.dfs.core.windows.net"
inputFolder = "facts/fctConversations"
outputStorageAccount = "MYSTORAGEACCOUNT.dfs.core.windows.net"
outputContainer = "sales"
# this needs to be different from inputFolder
# as we use a write then rename approach
outputFolder = "facts2/fctConversations"
archivesuffix = datetime.utcnow().strftime("%Y-%m-%d-%H%M")
archiveStorageAccount = "MYSTORAGEACCOUNT.dfs.core.windows.net"
archiveContainer = "salesarchive"
archiveFolder = 'facts/fctConversations-%s' %(archivesuffix)
# configure the date range of daily snapshots we are going to process
# set this to be the first daily snapshot date to process
start_date = date(2021, 11, 27)
# set this to be the most recent daily snapshot date to process
end_date = date(2023, 5, 3)
# we loop one day at a time
delta = timedelta(days=1)
Generating the updated fact table
from pyspark.sql import functions as F
import os.path
from os import path
processedDate = start_date
while (processedDate <= end_date):
processedDateString = processedDate.strftime("%Y-%m-%d")
print(processedDateString, end="\n")
filePath = 'abfss://{sourceContainer}@{storageAccount}/{sourceFolder}/processedDate={processedDateString}'\
.format(sourceContainer=inputContainer, storageAccount=inputStorageAccount, sourceFolder=inputFolder, processedDateString=processedDateString)
print ('reading from %s' %(filePath))
try:
inputDF = spark.read.parquet(filePath)
columns = inputDF.columns
for col in newcols:
if col not in columns:
inputDF = inputDF.withColumn(col, F.lit(None).cast('string'))
# uncomment these lines to check columns have been added
#columns2 = inputDF.columns
#for col in newcols:
# print('pre-write missing %s' %(col)) if col not in columns2 else 0
#write updated dataframe
outputPath = "abfss://{container}@{storageAccount}/{outputFolder}/processedDate={processedDateString}".format(
container=outputContainer, storageAccount=outputStorageAccount, outputFolder=outputFolder, processedDateString=processedDateString)
print('writing to: %s' %(outputPath))
inputDF.write.mode("append").parquet(outputPath)
# uncomment these lines to check file is updated by reading back
#print('checking: %s' %(outputPath))
#checkDF = spark.read.parquet(outputPath)
#checkcolumns = checkDF.columns
#for col in newcols:
# print('read-back missing %s' %(col)) if col not in checkcolumns else 0
except Exception as x:
print("Processing error!" + \
"\n" + "ERROR : " + str(x))
processedDate += delta
Moving the converted files into place
To finally replace the sales facts with our new table, we need to move the new set of files into the correct directory, deleting (or better, moving to archive) the original set.
I haven’t documented this as there are several approaches that can work, including a set of steps in a notebook (using from notebookutils import mssparkutils to access file move. copy and delete commands), in a Data Flow, or by direct interaction with the data lake storage account(s) using the Azure CLI.
Finishing up
Any consumers of the fact table will need to be updated to access the new columns. In our case this meant:
- regenerate the relevant view in the serverless SQL pool we use to make the data accessible from Power BI
- rebuild any Power BI model that consumes the table
Next steps
In the real world case behind this example, two of the extra columns were choice columns in the original Dynamics model. The approach in this note adds them as the choice value, but for easier reporting we will want to augment them with a second column for each one containing the corresponding label.
The code to do this will be in the next note.
#100DaysToOffload 31/100