Introduction
In the previous post I discussed adding new columns to historical snapshots of a fact table stored in Parquet format.
As a reminder, this work is within a datalake that is processing (amongst other sources) sales data from Dynamics 365:
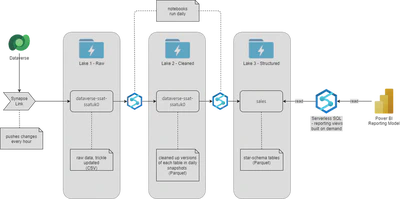
Two of the new columns I added were based on local optionset fields (or in the new nomenclature, choice columns) in the opportunity entity (table).
As these value fields contain an opaque integer, reporting would have to do a lookup to another dimension table containing the values.
Alternatively, and to make the reporting much simpler, I want to add additional columns to the fact table containing the label for each choice.
This work is split into these stages:
- modify the notebook that generates the fact table so that future daily snapshots have the label columns populated with the correct data
- create a copy of all the historical daily snapshots with the columns added if necessary, historically with a blank label (the sales team have only just started using these fields)
- manually replace the existing folder of fact snapshots with the folder containing the updated snapshots
- update the reporting views
- refresh the Power BI Model
Modifying the fact-builder notebook
This change has to do the following:
- load the data for the local optionsets from the “clean” datalake
- create two joins between our existing sales facts and the two optionsets, adding the label columns into the result
from datetime import date
from pyspark.sql import functions as F
processedDate = date.today()
processedDateString = processedDate.strftime("%Y-%m-%d")
sourceStorageAccount = 'MYCLEANLAKE.dfs.core.windows.net'
sourceContainer = 'MYDATAVERSECLEANCONTAINER'
# omitting all the existing code that builds
# the existing fact table in data frame fctConversations
# read in the cleaned optionset data
localOptionsSourceFolder = 'metadata/localoptionsets/processedDate={pd}/*.parquet'.format(pd=processedDateString)
localOptionsDF = spark.read.parquet('abfss://{sourceContainer}@{storageAccount}/{sourceFolder}'\
.format(sourceContainer=sourceContainer, storageAccount=sourceStorageAccount, sourceFolder=localOptionsSourceFolder))
localOptionsDF.printSchema()
The local optionsets dataframe has this schema:
root
|-- EntityName: string (nullable = true)
|-- OptionSetName: string (nullable = true)
|-- Option: long (nullable = true)
|-- LocalizedLabel: string (nullable = true)
For each of the optionset columns we are augmenting, we need to join our facts to a filtered view of the optionset data:
# filter out the optionset values for opportunity/ssat_category
oppCategoryOptionsDF = localOptionsDF \
.filter(localOptionsDF.EntityName == "opportunity") \
.filter((localOptionsDF.OptionSetName == 'ssat_category')) \
.withColumnRenamed("LocalizedLabel", "opp_categorylabel") \
.drop("EntityName") \
.drop("OptionSetName")
oppCategoryOptionsDF.show()
# join existing facts dataframe to the opportunity/ssat_category dataframe
# create new column opp_categorylabel containing the label text
if(('ssat_category' in fctConversations.columns) & ('opp_categorylabel' not in fctConversations.columns)):
categoryJoinDF = fctConversations.join(oppCategoryOptionsDF, fctConversations.ssat_category == oppCategoryOptionsDF.Option, "left") \
.drop('Option')
fctConversations = categoryJoinDF
# filter out the optionset values for opportunity/ssat_source
oppSourceOptionsDF = localOptionsDF \
.filter(localOptionsDF.EntityName == "opportunity") \
.filter((localOptionsDF.OptionSetName == 'ssat_source')) \
.withColumnRenamed("LocalizedLabel", "opp_sourcelabel") \
.drop("EntityName") \
.drop("OptionSetName")
oppSourceOptionsDF.show()
# join existing facts dataframe to the opportunity/ssat_source dataframe
# create new column opp_categorylabel containing the label text
if(('ssat_source' in fctConversations.columns) & ('opp_sourcelabel' not in fctConversations.columns)):
print("do source")
sourceJoinDF = fctConversations.join(oppSourceOptionsDF, fctConversations.ssat_source == oppSourceOptionsDF.Option, "left") \
.drop('Option')
fctConversations = sourceJoinDF
Adding the label columns to historical snapshots
This is done with the same process as shown in the previous post.
Manually move updated fact snapshots into place
Many ways of doing this, the simplest of which is just done with folder renames in the storage account
Update the reporting views
In the Azure portal, find the resource page for the Synapse Analytics workspace, and find the Serverless SQL endpoint:
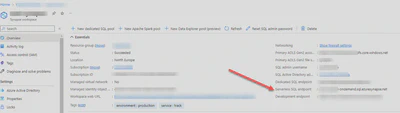
Install and open Azure Data Studio, and connect to the Serverless SQL Endpoint.
Open the view that is used to query the fact table, right click and select Script as Alter. This will generate a script that looks similar to this, just run it:
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER VIEW [funnel].[vwFctConversations] AS
SELECT fc.filepath(1) as ProcessedDate, *
FROM
OPENROWSET(
BULK 'facts/fctConversations/processedDate=*/*.snappy.parquet',
DATA_SOURCE = 'ExternalDataSourceDataLakeSales',
FORMAT='PARQUET'
) fc
WHERE
fc.filepath(1) = CONVERT(VARCHAR(20), CAST( GETDATE() AS Date ), 120)
GO
Refresh the Power BI Model
- Open the Power BI Model in Power BI Desktop
- Open the Data blade
- right click on the table that is mapped to the SQL view
- select Refresh Data
- if necessary, drag the new fields onto filters
- save the model, and if necessary republish to any Power BI workspaces you are using
#100DaysToOffload 31/100